

Photo by Pascal Müller on Unsplash
Mastering Pandas: 21 Pandas Tips Every Data Scientist Should Know
Maximize Your Pandas Skills: Essential Tips and Tricks for Mastering Data Manipulation


Table of contents
- 1: Print DataFrame in Markdown-friendly format
- 2: Group rows into a list
- 3: DataFrame.explode()
- 4: DataFrame.copy()
- 5: Groupby().count vs Groupby( ).size
- 6: Correlation
- 7: Cross-Tabulation
- 8: DataFrame.query()
- 9: Unpivot DataFrame
- 10: Rename aggregated column
- 11: Normalized Value Counts
- 12: df.transform() instead of df.count()
- 13: Fill in Null Values
- 14: Value Counts Missing Values
- 15: Filter Columns in DataFrame
- 16: Convert Data Types Automatically
- 17: Assign new columns to a DataFrame
- 18: Read HTML Tables
- 19: ‘nlargest’ and ‘nsmallest ‘
- 20: Create a Rank Column
- 21: Color Values in DataFrame
- Conclusion:
Whether you’re a beginner or an experienced data analyst, the 21 tips and tricks covered in this article will help you tackle any analytical task with ease. From writing clean code to avoiding reinventing the wheel, these tips will help you work smarter, not harder. Discover the hidden gems of Pandas and become a master user in no time. And if you have any additional tips to share, don’t hesitate to leave a comment.
1: Print DataFrame in Markdown-friendly format
Markdown is a lightweight markup language that is used to create formatted text using a plain-text editor. Sometimes, you might want to include a table in a markdown, such as GitHub README or Latex.
If you want to print a DataFrame in markdown format, use to_markdown() function.
import pandas as pd
df = pd.DataFrame({'a': [1, 2, 3, 4],
'b': [5, 6, 7, 8]})
# You can control the printing of the index column by using the flag index.
print(df.to_markdown(index=True))
| | a | b |
|---:|----:|----:|
| 0 | 1 | 5 |
| 1 | 2 | 6 |
| 2 | 3 | 7 |
| 3 | 4 | 8 |
# Ouput markdown with a tabulate option
print(df.to_markdown(tablefmt="grid", index=True))
# To create a markdown file from the dataframe, pass
# the file name as paramters
print(df.to_markdown("README.md", tablefmt="grid", index=True))
+----+-----+-----+
| | a | b |
+====+=====+=====+
| 0 | 1 | 5 |
+----+-----+-----+
| 1 | 2 | 6 |
+----+-----+-----+
| 2 | 3 | 7 |
+----+-----+-----+
| 3 | 4 | 8 |
+----+-----+-----+
2: Group rows into a list
It is common to use groupby to get the statistics of rows in the same group, such as count, mean, median, etc. If you want to group rows into a list instead, use “lambda x: list(x)”.
import pandas as pd
df = pd.DataFrame(
{
"col1": [1, 2, 3, 4, 3],
"col2": ["a", "a", "b", "b", "c"],
"col3": ["d", "e", "f", "g", "h"],
}
)
# Group by col2
print(df.groupby(["col2"]).agg(
{
"col1": "mean", # get mean
"col3": lambda x: list(x) # get list
}
))
col1 col3
col2
a 1.5 [d, e]
b 3.5 [f, g]
c 3.0 [h]
3: DataFrame.explode()
When working with a DataFrame, if you want to turn a string into a list and then split elements in a list into multiple rows, use the combination of str.split() and explode().
import pandas as pd
df = pd.DataFrame({"a": ["1,2", "4,5"],
"b": [11, 13]})
# Turn strings into lists
df.a = df.a.str.split(",")
print(df)
a b
0 [1, 2] 11
1 [4, 5] 13
a b
0 1 11
0 2 11
1 4 13
1 5 13
4: DataFrame.copy()
Have you ever tried to make a copy of a DataFrame user “=”? You will not get a copy but a reference to the original DataFrame. Thus, changing the new DataFrame will also change the original DataFrame.
A better way to make a copy is to use df.copy(). Now, changing the copy will not affect the original DataFrame.
import pandas as pd
df = pd.DataFrame({"col1": [1, 2, 3],
"col2": [4, 5, 6]})
df2 = df # Make a copy using =
df2["col1"] = [7, 8, 9]
df # df also changes
col1 col2
0 7 4
1 8 5
2 9 6
# Recrate df
df = pd.DataFrame({"col1": [1, 2, 3],
"col2": [4, 5, 6]})
df3 = df.copy() # Create a copy of df
df3["col1"] = [7, 8, 9]
df # df doesn't change
col1 col2
0 1 4
1 2 5
2 3 6
5: Groupby().count vs Groupby( ).size
If you want to get the count of elements in one column of a Pandas
DataFrame, usegroupbyandcount.If you want to get the size of groups composed of 2 or more columns, use
groupbyandsizeinstead.
import pandas as pd
df = pd.DataFrame(
{
"col1": ["a", "b", "b", "c", "c", "d"],
"col2": ["S", "S", "M", "L", "L", "L"]
}
)
# get the count of elements in one column
df.groupby(["col1"]).count()
col2
col1
a 1
b 2
c 2
d 1
# Get the size of groups of 2+ columns
df.groupby(["col1", "col2"]).size()
col1 col2
a S 1
b M 1
S 1
c L 2
d L 1
dtype: int64
6: Correlation
If you want to compute the correlation between rows or columns of two DataFrame, use .corrwith().
import pandas as pd
df1 = pd.DataFrame({
"a": [1, 2, 3, 4],
"b": [2, 3, 4, 6]
})
df2 = pd.DataFrame({
"a": [1, 2, 3, 3],
"b": [2, 2, 5, 4]
})
df1.corrwith(df2)
a 0.94388
b 0.68313
dtype: float64
7: Cross-Tabulation
Cross-tabulation allows you to analyze the relationship between multiple variables. To turn a Pandas DataFrame into a cross-tabulation, use pandas.crosstab().
import pandas as pd
network = [
("Ben", "Smith"),
("Ben", "Patrick"),
("Warren", "Jone"),
("Warren", "Smith"),
("Smith", "Patrick"),
]
# Create a dataframe of the network
friends1 = pd.DataFrame(
network, columns=["person1", "person2"]
)
# Create the order of the columns
friends2 = pd.DataFrame(
network, columns=["person2", "person1"]
)
# Create a symmetric dataframe
friends = pd.concat([friends1, friends2])
# Create a cross tabulation
pd.crosstab(friends.person1, friends.person2)
person2 Ben Jone Patrick Smith Warren
person1
Ben 0 0 1 1 0
Jone 0 0 0 0 1
Patrick 1 0 0 1 0
Smith 1 0 1 0 1
Warren 0 1 0 1 0
8: DataFrame.query()
It can be lengthy to filter columns of pandas DataFrame using brackets. To shorten the filtering statements, use df.query() instead.
import pandas as pd
df = pd.DataFrame({
"fruit": ["apple", "orange", "grape", "grape"],
"price": [4, 5, 6, 7]
})
# Filter using brackets
df[(df.price > 4) & (df.fruit == "grape")]
fruit price
2 grape 6
3 grape 7
# Filter using query
df.query("price > 4 & fruit == 'grape'")
fruit price
2 grape 6
3 grape 7
9: Unpivot DataFrame
If you want to unpivot a
DataFramefrom wide to long format, usepandas.melt().For example, you can use
pandas.melt()to turn multiple columns (“Aldi”, “Walmart”, “Costco”) into values of one column (“store”).
import pandas as pd
df = pd.DataFrame({
"fruit": ["apple", "orange"],
"Aldi": [4, 5],
"Walmart": [6, 7],
"Costco": [1, 2]
})
df
fruit Aldi Walmart Costco
0 apple 4 6 1
1 orange 5 7 2
# Turn Aldi, Walmart, Costco into values of "store"
df.melt(id_vars=["fruit"],
value_vars=["Aldi", "Walmart", "Costco"],
var_name='store')
fruit store value
0 apple Aldi 4
1 orange Aldi 5
2 apple Walmart 6
3 orange Walmart 7
4 apple Costco 1
5 orange Costco 2
10: Rename aggregated column
By default, aggregating a column returns the name of that column.
If you want to assign a new name to the aggregation, use name = (column, agg_method).
import pandas as pd
df = pd.DataFrame({"size": ["S", "S", "M", "L"],
"price": [44, 29.99, 10, 19]})
df.groupby('size').agg({'price': 'mean'})
price
size
L 19.000
M 10.000
S 36.995
# Assign name to the aggregation
df.groupby('size').agg(
mean_price=('price', 'mean')
)
mean_price
size
L 19.000
M 10.000
S 36.995
11: Normalized Value Counts
If you want to get the count of a value in a column, use
value_counts.However, if you want to get the percentage of a value in a column, add
normalize=Truetovalue_counts.
import pandas as pd
size = pd.Series(["S", "S", "M", "L", "S", "XL", "S", "M",])
# Get count of each value
size.value_counts()
S 4
M 2
L 1
XL 1
dtype: int64
# Get percentage of each value
size.value_counts(normalize=True)
S 0.500
M 0.250
L 0.125
XL 0.125
dtype: float64
12: df.transform() instead of df.count()
To filter pandas
DataFramebased on the occurrences of categories, you might attempt to usedf.groupbyanddf.count. However, since the Series returned by the count method is shorter than the originalDataFrame, you will get an error when filtering.Instead of using
count, usetransform. This method will return the Series with the same length as the originalDataFrame. Now you can filter without encountering any errors.
import pandas as pd
df = pd.DataFrame({
"type": ["A", "A", "O", "B", "O", "A"],
"value": [5, 3, 2, 1, 7, 3]
})
# Using count will throw an error because the
# Series returned is shorter than the original
# DataFrame
# df.loc[df.groupby("type")["type"].count() > 1]
df.loc[df.groupby("type")["type"].transform("size") > 1]
type value
0 A 5
1 A 3
2 O 2
4 O 7
5 A 3
13: Fill in Null Values
If you want to fill null values in one
DataFramewith non-null values at the same locations from anotherDataFrame, usepandas.DataFrame.combine_first.In the code below, the values at the first row of
store1are updated with the values at the first row ofstore2.
import pandas as pd
store1 = pd.DataFrame({
"orange": [None, 5, 9],
"apple": [4, None, 12]
})
store2 = pd.DataFrame({
"orange": [31, 52, 91],
"apple": [11, 71, 21]
})
# Fill null values of the store1 with values at the same
# locations from store2
store1.combine_first(store2)
orange apple
0 31.0 4.0
1 5.0 71.0
2 9.0 12.0
14: Value Counts Missing Values
By default, pandas.value_counts() ignore missing values. Pass dropna=False to make it count missing values.
import pandas as pd
size = pd.Series(["S", "S", None, "M", "L", "S", None, "XL", "S", "M",])
# Get count of each value, it does not count missing values
size.value_counts()
S 4
M 2
XL 1
L 1
dtype: int64
# pass dropna=False to get missing value count
size.value_counts(dropna=False)
S 4
M 2
NaN 2
XL 1
L 1
dtype: int64
15: Filter Columns in DataFrame
If you want to filter columns of a pandas DataFrame based on characters in their names, use DataFrame.filter. This can be handy if you create dummy variables and you want to select columns based on the prefix.
import pandas as pd
df = pd.DataFrame({'Temp': ['Hot', 'Cold', 'Warm', 'Cold'],
'Degree': [35, 3, 15, 2]})
print(df)
Temp Degree
0 Hot 35
1 Cold 3
2 Warm 15
3 Cold 2
df = pd.get_dummies(df, columns=['Temp'])
print(df)
Degree Temp_Cold Temp_Hot Temp_Warm
0 35 0 1 0
1 3 1 0 0
2 15 0 0 1
3 2 1 0 0
print(df.filter(like='Temp', axis=1))
Temp_Cold Temp_Hot Temp_Warm
0 0 1 0
1 1 0 0
2 0 0 1
3 1 0 0
16: Convert Data Types Automatically
If you don’t know the dtypes of columns in your DataFrame, you can use convert_dtypes() to quickly convert columns to the best possible types.
import pandas as pd
import numpy as np
df = pd.DataFrame(
{
"a": pd.Series([1, 2, 3], dtype=np.dtype("int32")),
"b": pd.Series(["x", "y", "z"], dtype=np.dtype("O")),
"c": pd.Series([True, False, np.nan], dtype=np.dtype("O")),
"d": pd.Series(["h", "i", np.nan], dtype=np.dtype("O")),
"e": pd.Series([10, np.nan, 20], dtype=np.dtype("float")),
"f": pd.Series([np.nan, 100.5, 200], dtype=np.dtype("float")),
}
)
df.dtypes
a int32
b object
c object
d object
e float64
f float64
dtype: object
new_df = df.convert_dtypes()
new_df.dtypes
a Int32
b string
c boolean
d string
e Int64
f Float64
dtype: object
17: Assign new columns to a DataFrame
Use Dataframe.assign() method to assign new columns to your DataFrame, Dataframe.assign() returns a new object (a copy) with the new columns added to the original ones. Existing columns that are re-assigned will be overwritten.
import pandas as pd
time_sentences = ["Saturday: Weekend (Not working day)",
"Sunday: Weekend (Not working day)",
"Monday: Doctor appointment at 2:45pm.",
"Tuesday: Dentist appointment at 11:30 am.",
"Wednesday: basketball game At 7:00pm",
"Thursday: Back home by 11:15 pm.",
"Friday: Take the train at 08:10 am."]
df = pd.DataFrame(time_sentences, columns=['text'])
# Use Assign instead of using direct assignment
# df['text'] = df.text.str.lower()
# df['text_len'] = df.text.str.len()
# df['word_count'] = df.text.str.count(" ") + 1
# df['weekend'] = df.text.str.contains("saturday|sunday", case=False)
print((
df
.assign(text=df.text.str.lower(),
text_len=df.text.str.len(),
word_count=df.text.str.count(" ") + 1,
weekend=df.text.str.contains("saturday|sunday", case=False),
)
))
text text_len word_count weekend
0 saturday: weekend (not working day) 35 5 True
1 sunday: weekend (not working day) 33 5 True
2 monday: doctor appointment at 2:45pm. 37 5 False
3 tuesday: dentist appointment at 11:30 am. 41 6 False
4 wednesday: basketball game at 7:00pm 36 5 False
5 thursday: back home by 11:15 pm. 32 6 False
6 friday: take the train at 08:10 am. 35 7 False
18: Read HTML Tables
.read_html() can be useful for quickly incorporating tables from various websites without figuring out how to scrape the site’s HTML.
import pandas as pd
# Without a marcher we will get a list of all tables in the
# page. To make a table selection, pass table title to the
# match parameter
table = pd.read_html(
"https://en.wikipedia.org/wiki/Minnesota",
match="Election results from statewide races"
)
print(table[0].head())
Year Office GOP DFL Others
0 2020 President 45.3% 52.4% 2.3%
1 2020 Senator 43.5% 48.8% 7.7%
2 2018 Governor 42.4% 53.9% 3.7%
3 2018 Senator 36.2% 60.3% 3.4%
4 2018 Senator 42.4% 53.0% 4.6%
table = pd.read_html(
"https://en.wikipedia.org/wiki/Minnesota",
match="Average daily"
)
print(table[0].head())
Location July (°F) July (°C) January (°F) January (°C)
0 Minneapolis 83/64 28/18 23/7 −4/−13
1 Saint Paul 83/63 28/17 23/6 −5/−14
2 Rochester 82/63 28/17 23/3 −5/−16
3 Duluth 76/55 24/13 19/1 −7/−17
4 St. Cloud 81/58 27/14 18/−1 −7/−18
19: ‘nlargest’ and ‘nsmallest ‘
Use .nlargest() and .nsmallest() to sort columns in DataFrame based on a specific column instead of using .sort_values()
Data Link: IMDB Rating
import pandas as pd
df = pd.read_csv('data/imdbratings.csv',
usecols=['star_rating', 'title', 'genre', 'duration'])
print(df.head())
star_rating title genre duration
0 9.3 The Shawshank Redemption Crime 142
1 9.2 The Godfather Crime 175
2 9.1 The Godfather: Part II Crime 200
3 9.0 The Dark Knight Action 152
4 8.9 Pulp Fiction Crime 154
print(df.nlargest(5, "duration"))
star_rating title genre duration
476 7.8 Hamlet Drama 242
157 8.2 Gone with the Wind Drama 238
78 8.4 Once Upon a Time in America Crime 229
142 8.3 Lagaan: Once Upon a Time in India Adventure 224
445 7.9 The Ten Commandments Adventure 220
print(df.nsmallest(5, "duration"))
star_rating title genre duration
389 8.0 Freaks Drama 64
338 8.0 Battleship Potemkin History 66
258 8.1 The Cabinet of Dr. Caligari Crime 67
88 8.4 The Kid Comedy 68
293 8.1 Duck Soup Comedy 68
20: Create a Rank Column
Pandas DataFrame.rank() method returns a rank of every respective index of a series passed. The rank is returned based on position after sorting.
In the following example, a new Rank column is created, which ranks the Student by their Marks.
import pandas as pd
df = pd.DataFrame({'Students': ['John', 'Smith', 'Patrick', 'Bob', 'Jose'],
'Marks': [80, 56, 95, 75, 45]})
print(df)
Students Marks
0 John 80
1 Smith 56
2 Patrick 95
3 Bob 75
4 Jose 45
df["Rank"] = df["Marks"].rank(ascending=False)
print(df)
Students Marks Rank
0 John 80 2.0
1 Smith 56 4.0
2 Patrick 95 1.0
3 Bob 75 3.0
4 Jose 45 5.0
21: Color Values in DataFrame
Color styling adds more readability to the end user. Pandas have the style property that follows us to apply different styles to DataFrames.
import pandas as pd
df = pd.DataFrame({'Students': ['John', 'Smith', 'Patrick', 'Bob', 'Jose'],
'Physics': [80, 56, 95, 75, 45],
'Mathematics': [90, 85, 55, 65, 75]})
df.set_index('Students', inplace=True)
df
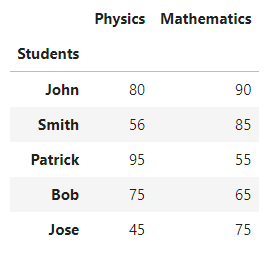
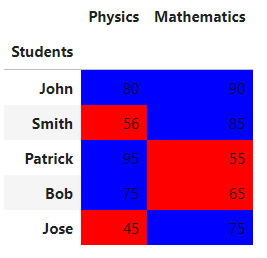
def pass_condition(val):
color = 'blue' if val > 70 else 'red'
return f"background-color: {color}"
df.style.applymap(pass_condition)
Conclusion:
Pandas is a powerful, flexible, and easy-to-use open-source library for data analysis and manipulation, built on the foundation of Python programming. Becoming a master of Pandas can significantly enhance your data analysis skills, and knowing the best practices can save you considerable time and effort. With its fast performance and intuitive syntax, Pandas is the go-to choice for data scientists and analysts worldwide. By mastering Pandas, you’ll be able to manipulate, analyze, and visualize data with ease, giving you a significant advantage in today’s data-driven world.